The blist package is pretty good. The documentation and care the author has put in is very impressive. It's a shame that it wasn't included in the standard Python distribution, and the reasons given seem to indicate to me that there are not enough people working on large datasets on the Python committee. Any how, I wanted to try out for myself how the sorted list stacks up against a regular python list that is sorted every time after and insertion:

As can be seen, blist.sorted insertion is O(1) and compares quite favorably to the regular Python list.
Timing code follows:
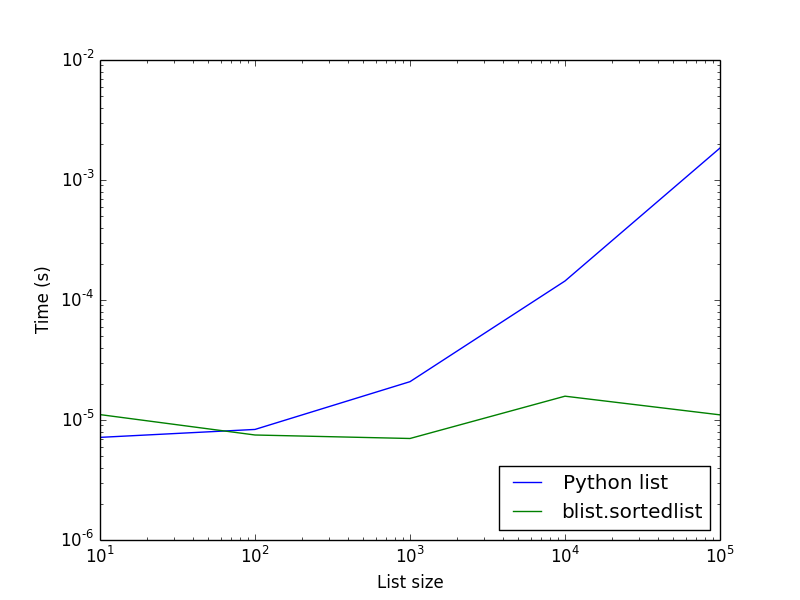
As can be seen, blist.sorted insertion is O(1) and compares quite favorably to the regular Python list.
Timing code follows:
import pylab
from timeit import timeit
l = [1,2,3,4,5,6,7,8,9,10]
def time_things():
n_loops = 1000
s = [10, 100, 1000, 10000, 100000]
blist_time = [timeit("a.add(100)", "import blist; a=blist.sortedlist(range({:d},0,-1))".format(n), number=n_loops)/n_loops for n in s]
list_time = [timeit("a.append(100); a.sort()", "a=range({:d})".format(n), number=n_loops)/n_loops for n in s]
return list_time, blist_time
def plot_things(list_time, blist_time):
s = [10, 100, 1000, 10000, 100000]
pylab.plot(s, list_time, label='Python list')
pylab.plot(s, blist_time, label='blist.sortedlist')
pylab.setp(pylab.gca(), xlabel='List size', ylabel='Time (s)', xscale='log', yscale='log') #, ylim=[1e-9, 1e-3])
pylab.legend(loc='lower right')
Comments
Post a Comment